DOM
# DOM
DOM(文档对象模型)是针对于 xml 但是扩展用于 HTML 的应用程序编程接口,定义了访问和操作 HTML 的文档的标准。
定义了中立于平台和语言之间的接口,真正的跨平台。它允许程序和脚本动态的访问和更新文档的内容、结构、样式。
总之 DOM 是关于如何获取、修改、添加和删除 HTML 元素的标准。
IE8 及更低版本中的 DOM 是 COM 对象实现的,这意味着这些版本的 IE 中,DOM 对象和原生对象具有不同的行为和功能
# 节点层级
# Node 类型
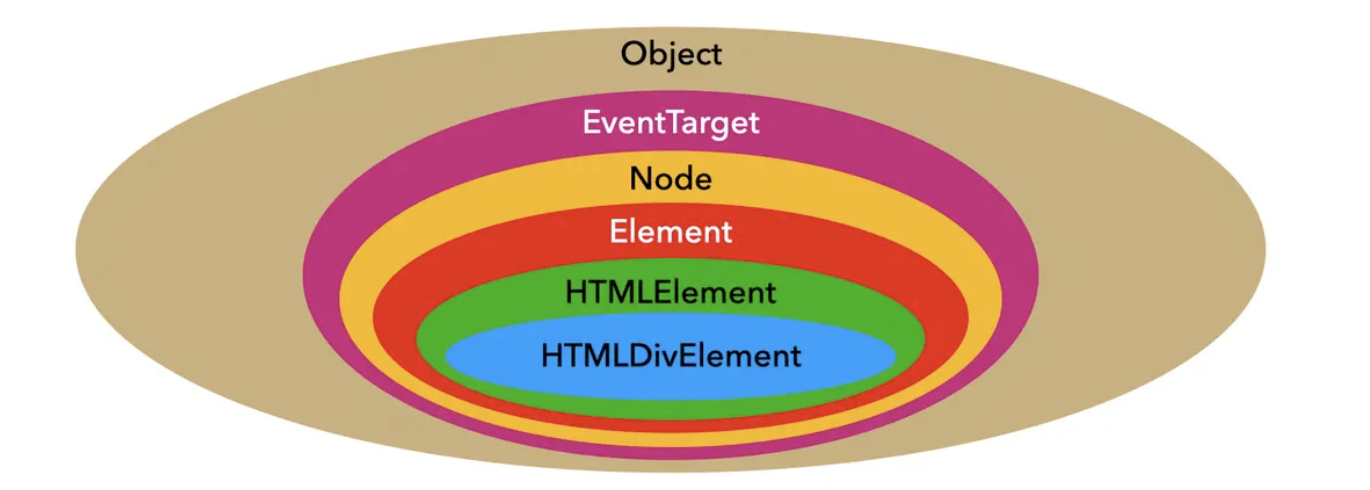
在 JavaScript 中所有节点类型都继承自 Node 类型,所以这些节点类型都拥有着 Node 类型定义的属性和方法。
所有节点类型都拥有nodeType属性,用于表明该节点的类型。节点类型由在 Node 类型中定义的下列 12 个数值常量来表示,任何节点类型必然是其中一种。
换行符 \n 被当成一个单独的 Node。《精读》请问 Node 和 Element 有何区别? (opens new window)
| Node 类型 | 数值常量 | 描述 |
|---|---|---|
Node.ELEMENT_NODE | 1 | 元素,例如 <div> |
Node.ATTRIBUTE_NODE | 2 | 属性 |
Node.TEXT_NODE | 3 | 文本节点 |
Node.CDATA_SECTION_NODE | 4 | 文档中的 CDATA 部(不会由解析器解析的文本) |
Node.ENTITY_REFERENCE_NODE | 5 | 实体引用 |
Node.ENTITY_NODE | 6 | 实体 |
Node.PROCESSING_INSTRUCTION_NODE | 7 | 处理指令 |
Node.COMMENT_NODE | 8 | 注释 |
Node.DOCUMENT_NODE | 9 | 整个文档 |
Node.DOCUMENT_TYPE_NODE | 10 | 向为文档定义的实体提供接口 |
Node.DOCUMENT_FRAGMENT_NODE | 11 | 轻量级的 Document 对象(文档的某个部分) |
Node.NOTATION_NODE | 12 | DTD 中声明的符号 |
# DOM 操作
# 获取/设置元素的属性值:
// 括号传入属性名,返回对应属性的属性值
element.getAttribute(attributeName);
// 传入属性名及设置的值
element.setAttribute(attributeName, attributeValue);
# 创建节点 Node
// 创建一个html元素,这里以创建h3元素为例
document.createElement('h3');
// 创建一个文本节点;
document.createTextNode(String);
// 创建一个属性节点,这里以创建class属性为例
document.createAttribute('class');
# 增加节点
// 往element内部最后面添加一个节点,参数是节点类型,类似push操作
element.appendChild(Node);
// 在element内部的中在existingNode前面插入newNode,类似unshift操作
elelment.insertBefore(newNode, existingNode);
# 删除节点
// 删除当前节点下指定的子节点,删除成功返回该被删除的节点,否则返回null
let user0 = document.getElementsByClassName('user')[0];
document.getElementById('users').removeChild(user0);
// remove 方法不太常见,直接在当前节点使用 remove() 方法就可以删除该节点,无返回值
document.getElementsByClassName('user')[0].remove();
# 改动节点
replaceChild用于替换 childNodes 列表中某个特定的节点,并返回被移除的节点。
// 移除第一个子节点
var formerFirstChild = someNode.removeChild(someNode.firstChild);
// 移除最后一个子节点
var formerLastChild = someNode.removeChild(someNode.lastChild);
# 查找节点
// 它们选择的对象可以是标签,可以是类(需要加点),可以是 ID(需要加#)
document.querySelector();
document.querySelectorAll();
// 通过id号来获取元素,返回一个元素对象
document.getElementById(idName);
// 通过name属性获取id号,返回元素对象数组
document.getElementsByName(name); // 注意是`getElements`,这个s容易漏掉
// 通过class来获取元素,返回元素对象数组
document.getElementsByClassName(className); // 注意是`getElements`,这个s容易漏掉
// 通过标签名获取元素,返回元素对象数组
document.getElementsByTagName(tagName); // 注意是`getElements`,这个s容易漏掉
拓展知识:
QuerySelector/QuerySelectorAll 和 getElementById/getElementsByClassName 的区别 (opens new window)
为什么 getElementsByTagName 比 querySelectorAll 方法快 (opens new window)
# 复制节点
cloneNode接受一个布尔值作为参数,表示是否执行深复制。
在参数为 true 时,执行深复制,也就是复制节点及整个子节点树。
在参数为 false 的情况下,执行浅复制,即复制节点本身。
// 调用者是要被复制的 node,返回值是这个 node 的副本
let dupUsers = document.getElementById('users').cloneNode(true);
⚠️ 注意: 由于不同版本规范中 cloneNode 方法的默认参数不同,所以请一定加上参数
# 替换节点
replaceChild 接收的两个参数是要插入的节点和要替换的节点,要替换的节点将由这个方法返回并从文档树中移除,同时由要插入的节点占据其位置。
先创建另一个子节点,然后父节点.replaceChild(刚创建的子节点, 要被替换的子节点)。
// 父节点调用,用tempLi替换0号子节点
let tempLi = document.createElement('li');
tempLi.innerText = '替换节点';
document
.getElementById('users')
.replaceChild(tempLi, document.getElementsByClassName('user')[0]);
# 终极大招 innerHTML
上述提到的所有问题,都可以通过 innerHTML 解决
这个方法和前文中提到的 innerText 很相似
- 在读模式下,返回与调用元素的所有子节点(包括元素、注释和文本节点)对应的 HTML 字符串;
- 在写模式下,innerHTML 会根据指定的值创建新的 DOM 树,然后用这个 DOM 树完全替换调用元素原先的所有子节点
我们可以在读模式下获取到我们要操作的 node 或者他的 父节点,之后通过字符串处理方法进行操作,然后再写入
但是我们一般不会这样做
主要是因为它存在安全问题,innerHTML 不会检查代码,直接运行,会有风险
所以 innerHTML 方法建议仅用于新的节点,比如创建插入,内容最好是可控的,而不是用户填写的内容
// 拿到指定内容
document.querySelector('.xxx或者#xxx').innerHTML;
// 把指定元素里面的内容换成 = 后面的内容
document.querySelector('.xxx或者#xxx').innerHTML = '<div>我是魔法值盒子</div>';
被玩坏的 innerHTML、innerText、textContent 和 value 属性 (opens new window)
# MutationObserver
变化观察者可以在 DOM 被修改时异步执行回调(本身是一个微任务)。
使用 MutationObserver 可以观察整个文档、dom 树的一部分、某个元素。
还可以观察元素属性、子节点、文本,或者前三者的任意组合变化。
// 选择需要观察变动的节点
const targetNode = document.getElementById('some-id');
// 观察器的配置(需要观察什么变动)
const config = { attributes: true, childList: true, subtree: true };
// 当观察到变动时执行的回调函数
const callback = function (mutationsList, observer) {
// Use traditional 'for loops' for IE 11
for (let mutation of mutationsList) {
if (mutation.type === 'childList') {
console.log('A child node has been added or removed.');
} else if (mutation.type === 'attributes') {
console.log('The ' + mutation.attributeName + ' attribute was modified.');
}
}
};
// 创建一个观察器实例并传入回调函数
const observer = new MutationObserver(callback);
// 以上述配置开始观察目标节点
observer.observe(targetNode, config);
// 之后,可停止观察
observer.disconnect();
详见红宝书 p433
MDN-how to use MutationObserver (opens new window)
# DOM0、1、2、3、4 是啥
DOM 规范制定的一个演进过程,逐渐扩展 DOM API,满足 XML 的所有需求并提供更好的错误处理和特性检测。
onclick,onxxx 系列是 DOM0 级别的事件,只能有一个函数,一定条件下可以被复制。- 大家熟知的
Node,document,document.createElement都是在 DOM1 级别定义的。 addEventListner,document.body.style,getElementById这些都是 DOM2 级别的东西。XPath属于 DOM3 级别的东西,平时并不常见,其也可用于遍历节点。- DOM4,增加了 MutationObserver,提供观察节点变化的能力。